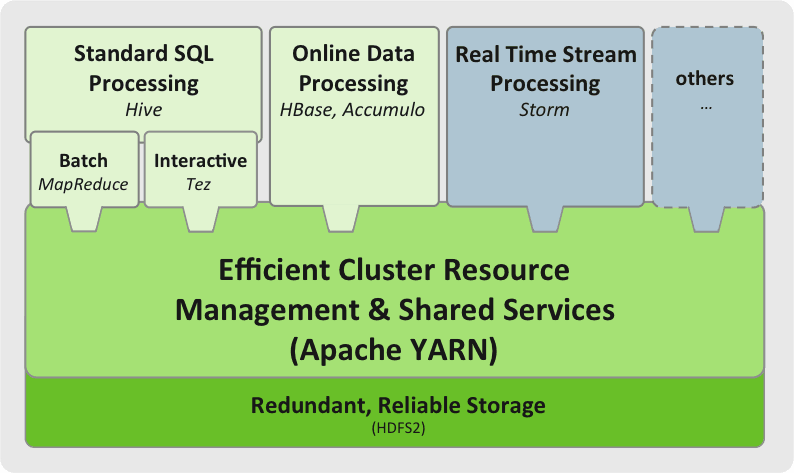
Apache Hadoop YARN is the data operating system for Hadoop 2.0. YARNenables a user to interact with all data in multiple ways simultaneously, making Hadoop a true multi-use data platform and allowing it to take its place in a modern data architecture.
Initiative Goals
Flexibility
Enable data processing models beyond MapReduce (batch) such as interactive, streaming and beyond.
Efficiency
Double the processing IN Hadoop on the same hardware while providing predictable performance and quality of service.
Resource Sharing
Provide a stable, common set of shared resources across multiple, co-ordinated workloads IN Hadoop.
Status
The genesis of YARN and Hadoop 2 is via a Jira ticket (MAPREDUCE-279) raised in January 2008 by Hortonworks co-founder Arun Murthy. YARN is the result of 5 years of development and forms part of Hadoop as Apache Hadoop YARN.

YARN has been tested by Yahoo! since September 2012 and has been in production across 30,000 nodes and 325PB of data since January 2013. More recently, other enterprises such as Microsoft, EBay, Twitter and Xing have adopted a YARN-based architecture.
Flexibility
By separating the original processing engine of Hadoop (MapReduce) from the resource management, then YARN is effectively an operating system for Hadoop. This means that many different processing engines can operate simultaneously across a Hadoop cluster.

Efficiency & Shared
YARN has been shown to enable double the processing in Hadoop on the same hardware providing predictable performance and quality of service. YARN provides a fabric of stable, shared resources across multiple co-ordinated workloads.
- Management and Monitoring.
- Multi-tenancy.
- Security.
- High Availability.
- Disaster Recovery.
No comments:
Post a Comment